Grundläggande Textanalys: Uppgift 2
Denna uppgift handlar om ordklasstaggning och Markov-modeller. Den praktiska delen består i att träna och utvärdera taggare med systemet HunPos. Den teoretiska delen består av frågor om Markov-modeller och närbesläktade n-gram-modeller. Det finns dessutom en tilläggsuppgift för dem som vill ha betyget VG.
1. Ordklasstaggning med HunPoS
Den första uppgiften är att träna ordklasstaggare för svenska med data från Stockholm-Umeå-korpusen (SUC) och systemet HunPos samt utvärdera korrektheten på en särskild testmängd från SUC (som är skild från träningsmängden). De filer som ska användas finns i /local/kurs/gta14/ på STP-systemet:
- suc-train.txt (manuellt taggad träningsmängd)
- suc-test.in (otaggad testmängd)
- suc-test.txt (manuellt tagged testmängd för utvärdering)
- suc-train.lex (lexikon för utvärdering)
För att träna en ordklasstaggare används kommandot hunpos-train med namnet på den modell man vill skapa som argument. Träningsdata läses från stdin. För att träna modellen mymodel med default-inställningar blir det alltså:
hunpos-train mymodel < suc-train.txt
För att tagga ny text används kommandot hunpos-tag med modellnamnet som argument och indata från stdin och utdata till stdout. Om vi döper utfilen till suc-test.out blir det alltså:
hunpos-tag mymodel < suc-test.in > suc-test.out
För utvärdering används kommandot tnt-diff som anropas enligt följande:
tnt-diff -l suc-train suc-test.txt suc-test.out
Flaggan -l suc-train behövs för att tnt-diff ska ge olika statistik för kända och okända ord med hjälp av lexikonfilen suc-train.lex.
HunPos har ett antal parametrar som kan varieras för att skapa olika modeller. Du ska i första hand jämföra en bigram- och en trigram-modell för vilket du behöver använda flaggan -t, men det är förstås fritt fram att testa andra parametrar också. Kolla användarmanualen för HunPos på https://code.google.com/p/hunpos/wiki/UserManualI för mer information.
2. N-gram-modeller
För denna uppgift ska du använda ett litet stickprov av SUC och själv beräkna bigramsannolikheter för ordklasser med additiv smoothning (add-1, Laplace). Använd bara SUC:s basordklasser och använd <s> som en dummy-tag för startsannolikheter. Observera att sannolikheterna ska vara definierade för alla möjliga bigram, inte bara för dem som faktiskt förekommer i stickprovet. Redovisa resultatet i form av en tabell med 26 x 25 = 650 rader, vars början har följande form:
<s> AB : 0.0375 <s> DT : 0.075 ... AB AB : 0.120481927711 AB DT : 0.0240963855422 ...Här är listan över SUC:s basordklasser:
AB DT HA HD HP HS IE IN JJ KN MAD MID NN PAD PC PL PM PN PP PS RG RO SN UO VBOch stickproven finns på denna sida.
3. Markov-modeller
Nedan visas en Markov-modell med två tillstånd Ko och Anka, samt ett start- och ett slut-tillstånd. Symbolsannolikheter:
- I tillstånd Ko genererar modellen Mu med sannolikhet 0.9 och Hej med sannolikhet 0.1.
- I tillstånd Anka genererar modellen Kvack med sannolikhet 0.6 och Hej med sannolikhet 0.4. (Ankan är bättre på svenska än kon.)
- I start- och sluttillståndet genereras ingenting.
- Från start-tillståndet går modellen till tillstånd Ko med sannolikhet 0.5 och till tillstånd Anka med sannolikhet 0.5.
- Från tillstånd Ko stannar modellen i tillstånd Ko med sannolikhet 0.5, går till tillstånd Anka med sannolikhet 0.3 och till slut-tillståndet med sannolikhet 0.2.
- Från tillstånd Anka stannar modellen i tillstånd Anka med sannolikhet 0.5, går till tillstånd Ko med sannolikhet 0.3 och till slut-tillståndet med sannolikhet 0.2.
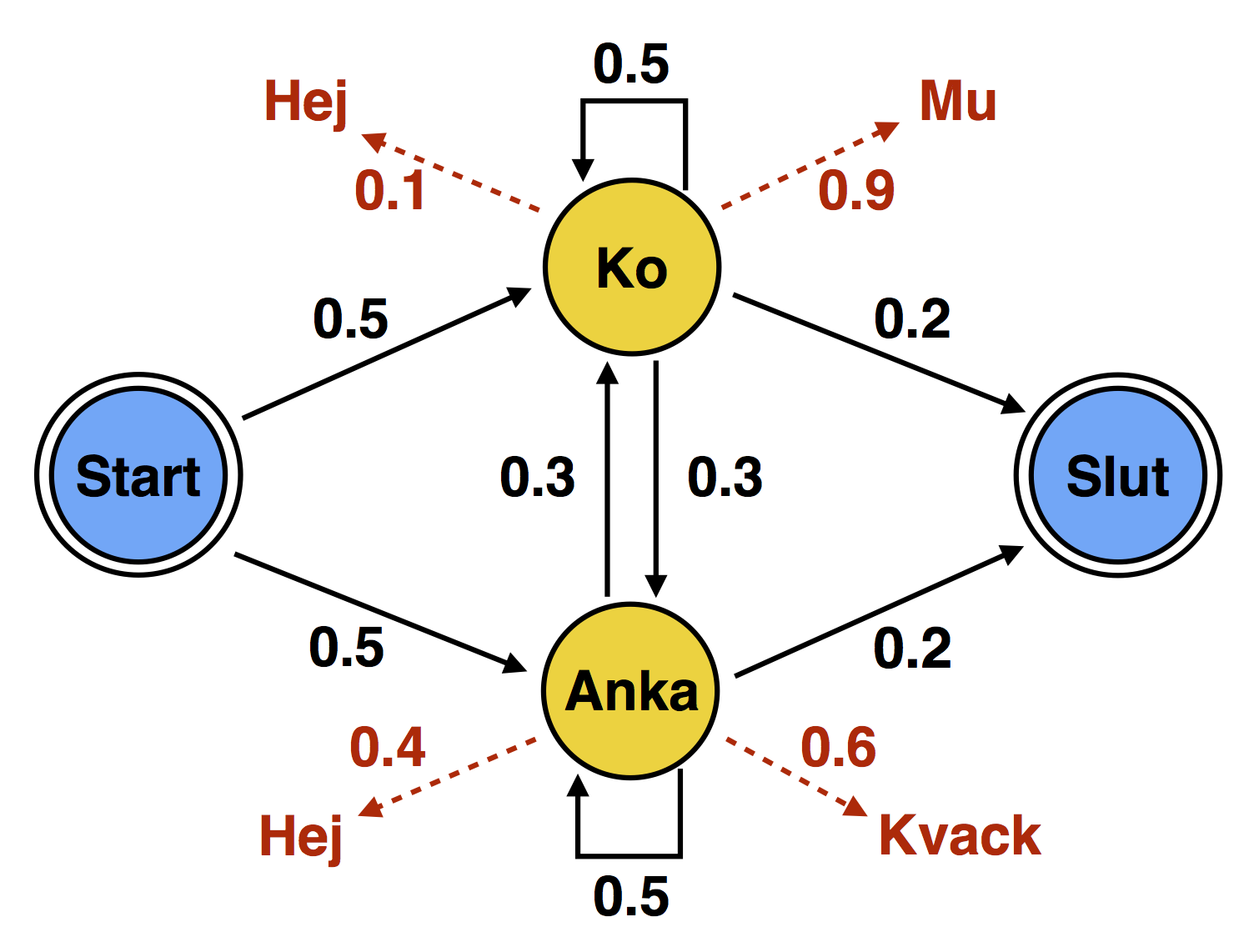
En symbolsekvens S = s1, ..., sn genereras genom att modellen startar i start-tillståndet och därefter gör n transitioner till något av tillstånden Ko och Anka och i varje tillstånd genererar någon av symbolerna Mu, Hej och Kvack, för att till sist gå till slut-tillståndet.
Besvara följande frågor för den symbolsekvens S du tilldelas på denna sida:
- Vilken är den mest sannolika tillståndssekvens som genererar S?
- Vilken sannolikhet har S enligt modellen?
Båda svaren ska motiveras med uträkningar eller logiska argument, men du behöver inte använda formella algoritmer som Viterbi, Forward eller Backward.
4. För VG
För betyget VG krävs förutom de tre obligatoriska uppgifterna ovan någon av följande utvidningar:
- Gör en noggrann utforskning av hur HunPos' suffixanalys påverkar taggningsresultatet för okända ord.
- Beräkna bigramsannolikheterna i deluppgift 2 med någon av de andra regulariseringsmetoder som behandlas i Jurafsky & Martin.
- Visa i detalj hur man beräknar lösningarna i deluppgift 3 med Viterbis algoritm respektive forward- eller backward-algoritmen.
Rapport
Skriv en rapport som visar hur du löst uppgifterna. Rapporten bör vara 2-4 sidor om bara de obligatoriska uppgifterna gjorts och 3-5 sidor för VG (exklusive den stora tabellen i uppgift 2). Skicka rapporten i ren text till joakim.nivre@lingfil.uu.se senast den 20 maj 2014.